Inside Git: How It Works and the Role of the .git Folder
While learning Git I spent a lot of time using it without really knowing what was happening in the background.
Commands worked projects moved forward and that felt enough most of the time. But whenever something went wrong Git suddenly felt unpredictable. That’s when it became clear that the problem wasn’t Git it was my understanding of it.
This blog is about the internal side of Git that helped things finally make sense for me especially the role of the .git folder.
How Git Works Internally
One of the biggest misunderstandings I had early on was thinking that Git tracks files.
It doesn’t.
Git tracks content.
Git doesn’t really care about file names or folder paths. It only cares about what’s inside a file. If the content hasn’t changed Git doesn’t store it again. If it has changed Git treats it as something new.
Another important realization was that Git doesn’t store changes. Every commit is a snapshot of the project at a specific moment. Thinking in snapshots instead of differences made Git feel much more logical.
Understanding the .git Folder
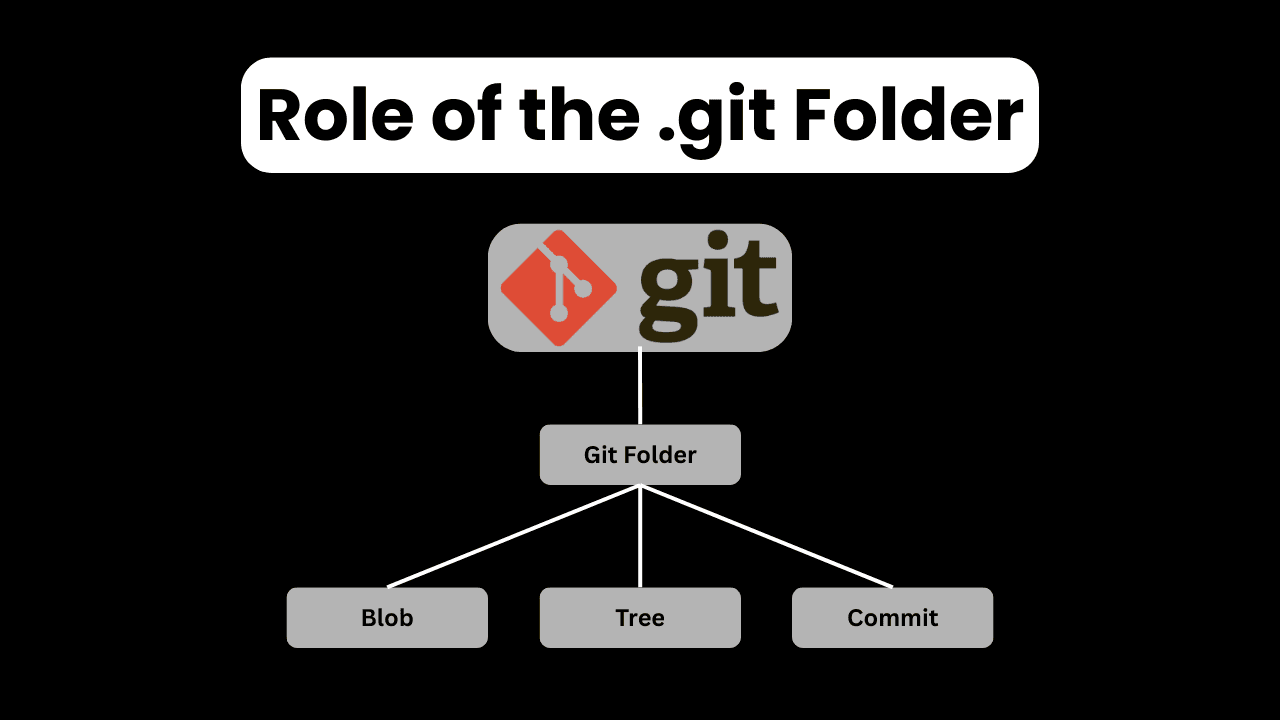
The .git folder is the core of every Git repository.
When git init is run this folder is created. From that point on Git depends entirely on this folder to understand the project’s history, structure and current state.
The .git folder looks like this:

This folder may look intimidating at first but each part has a clear role.
What Each File and Folder Inside .git Does
hooks/
The hooks folder contains scripts that Git can run automatically during certain actions.
Examples include:
before a commit
after a commit
before a push
By default these scripts are inactive. They exist to allow automation and custom checks.
info/
The info folder stores additional repository information.
One common use is excluding files locally without using .gitignore. This folder is less commonly used but still part of Git’s internal structure.
objects/
This is where Git stores actual data.
Every blob, tree and commit lives inside the objects directory. Git names these objects using hashes which makes them unique and secure.
If something exists in Git history it exists here in some form.
refs/
The refs directory stores pointers.
These pointers reference commits and are used for:
branches
tags
remote references
For example a branch name doesn’t store code. It simply points to a specific commit inside objects.
config
The config file stores repository specific settings.
This includes:
user information (for this repo)
remote repository URLs
custom Git behavior
These settings apply only to the current repository.
HEAD
HEAD tells Git where the current position is.
It usually points to a branch and that branch points to a commit. When a new commit is created HEAD moves forward with it.
In simple terms HEAD answers the question
“Which commit am I on right now?”
Git Objects: Blob, Tree, Commit
Git stores data using objects. Understanding these objects made Git’s behavior much clearer to me.
Blob
A blob stores the content of a file.
It does not store the file name or location. If two files have the same content Git stores only one blob.

Tree
A tree represents the structure of the project.
It connects file names to blobs and folder names to other trees.

Trees explain how Git knows which file belongs where.
Commit
A commit ties everything together.
A commit points to:
a tree (project structure)
a parent commit
metadata (message, author, time)

A commit is a full snapshot not just a list of changes.
Relationship Between Commits, Trees and Blobs

This relationship explains almost everything Git does internally.
How Git Tracks Changes
Git does not track changes line by line.
Instead Git checks file content:
If content changed = new blob
If content didn’t change = reuse existing blob
This explains why Git is fast and why unchanged files don’t get duplicated across commits.
What Happens During git add
When git add is run nothing is saved permanently.
Internally Git:
takes file content
creates a blob
stores it in
objects/updates the staging area (
index)

At this stage history is still untouched.
What Happens During git commit
This is when history actually changes.
When git commit runs Git:
reads the staging area
builds a tree
creates a commit object
links it to the previous commit
moves HEAD forward

How Git Uses Hashes
Every object in Git is identified by a hash.
Hashes are generated from content. Even a small change produces a completely different hash. This ensures data integrity and prevents silent changes.
Hashes are the reason Git history is reliable and trustworthy.
The Mental Model That Helped Me
What helped me most was stopping the habit of memorizing commands.
Instead I started thinking of Git as:
content stored as blobs
structure stored as trees
snapshots stored as commits
history built by linking commits
Once this model became clear Git felt predictable instead of risky.
Final Thoughts
Understanding Git internals wasn’t required to use Git but it completely changed how confidently I worked with it.
Instead of guessing or relying on trial and error Git started to feel logical. Looking inside how Git works removed a lot of fear around version control.